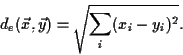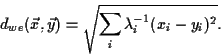For classification we apply the nearest-neighbour (NN) and the
minimum distance (to class mean) (MD) classifier. As a measure of
distance in feature space, a natural choice is the usual
Euclidian metric (E)
Table 1 and 2 show the results from the
nearest neighbour and minimum distance classifiers. We compare the feature
extraction methods mentioned earlier (eigenfeatures (PCA) and Gabor), with
simply using gray-levels (GL), either pixel values or pixel values
after resizing the image (
![]() or
or ![]() ). In these cases the
feature
vectors just consist of the pixel values of the vectorized image, e.g.
for the simplest case (no resizing) we have a 625-dimensional feature
vector (from a
). In these cases the
feature
vectors just consist of the pixel values of the vectorized image, e.g.
for the simplest case (no resizing) we have a 625-dimensional feature
vector (from a
![]() image). All the scores are percentage
correct classification averaged over 10 trials, when the dataset of 400
images is randomly divided into 2 equally sized sets (5 images for
training and 5 images for testing for each subject). This methodology is
equivalent to the approaches usually taken when working with the ORL
database, which allows us to compare with other systems.
image). All the scores are percentage
correct classification averaged over 10 trials, when the dataset of 400
images is randomly divided into 2 equally sized sets (5 images for
training and 5 images for testing for each subject). This methodology is
equivalent to the approaches usually taken when working with the ORL
database, which allows us to compare with other systems.
We observe from the experiments that we get surprisingly good results from just the eyes compared to using the whole face. The best reported results when using the whole face is significantly better of course, but from the sample images shown in figure 1 (observe the large variation), 85% correct classification is very satisfying. A bit surprising is that using simple gray-level values as features yields competitive performance. However, similar results for using the nearest neighbour on gray-level values from the entire face have been reporteded earlier [6]. We should take this as an indication that we need further testing, specifically on a larger dataset, to validate our results.
The best results are obtained with the Gabor feature extraction method. However, we should note that there was a large degree of variation in the 10 trials (due to the process of randomly dividing the set into training and test set), so there is a question of the statistical significance of these results. But since the overall 3 best results all are from Gabor, we consider this a strong indication that this method is the best compared to our implementations of the eigenfeatures and gray-levels here.
As mentioned earlier, it is difficult to select the number of eigeneyes to use for spanning the subspace. We want to keep our feature space as low-dimensional as possible, which would initially lead us to discard some eigeneyes (and perhaps the ones with the smallest corresponding eigenvalues). We see from our results that this would lead to sub-optimal performance, since the best result obtained in our experiments when using this technique is when we keep all the 200 eigeneyes (84.4% with MD classifier and CBD metric).
It is also noteworthy to mention that there is a significant difference in performance for the different metrics. We cannot derive any general rule-of-thumb for this, but we can note that the weighted euclidian metric did poorly for large feature space with the nearest neighbour classifier. It is also the worst metric for the highest dimensions (PCA 100 and 200) with the minimum distance classifier. Both these cases is probably due to inaccurate estimated eigenvalues for the last principal components (eigeneyes), which is caused by a too small training set (from which the principal components were computed). Otherwise, the general observation is that one metric is clearly to prefer instead of another (which is typical for pattern recognition applications).
All the results we have presented here can be considered as preliminary since there are many potential parameter adjustments and classification strategies we can apply. For the eigenfeature case, we could either compute a subspace from the entire eye-area instead of separate eyes or we could try further normalization as mentioned earlier. There is no reason to believe that we are using the optimal Gabor wavelets either. We could further experiment with both size and rotation. Future work might also include looking into some strategy such as classifying from just one eye, and select that eye based upon some similarity criteria (to yield further robustness in cases where one eye might be completely covered).
| Method | NN | |||
| de | dwe | dabc | dcbd | |
| GL
|
77.0 | - | 81.1 | 82.6 |
| GL
|
80.8 | - | 82.2 | 83.4 |
| GL |
78.6 | - | 78.9 | 80.2 |
| PCA 10 | 70.5 | 72.0 | 70.9 | 71.4 |
| PCA 50 | 75.9 | 63.8 | 80.3 | 76.6 |
| PCA 100 | 75.1 | 51.4 | 79.6 | 72.7 |
| PCA 200 | 77.4 | 58.4 | 80.8 | 75.1 |
| Gabor | 84.6 | - | 84.6 | 85.2 |
| Method | MD | |||
| de | dwe | dabc | dcbd | |
| GL
|
76.2 | - | 75.7 | 77.0 |
| GL
|
76.7 | - | 76.5 | 77.3 |
| GL |
70.7 | - | 70.6 | 70.8 |
| PCA 10 | 64.1 | 68.2 | 62.6 | 65.8 |
| PCA 50 | 74.9 | 78.3 | 74.7 | 79.6 |
| PCA 100 | 76.4 | 75.0 | 75.6 | 81.8 |
| PCA 200 | 76.2 | 71.8 | 75.5 | 84.4 |
| Gabor | 77.4 | - | 76.7 | 74.5 |