We use the face database from Olivetti Research Lab. This database has
been widely used for testing face recognition systems, and the best
reported result to our knowledge is 96% correct classification
[6], when the database is divided into two equally large sets
(for training and testing). The database contains 10 images of 40 subjects
for a total of 400 images. The images are gray-level of size
![]() .
We have manually located the center of the eyes in all the
images, and then extracted a
.
We have manually located the center of the eyes in all the
images, and then extracted a
![]() window at this region (for both
eyes). If this subwindow includes an area outside the original face image,
we pad the image with the mean of the gray-level values in the full face
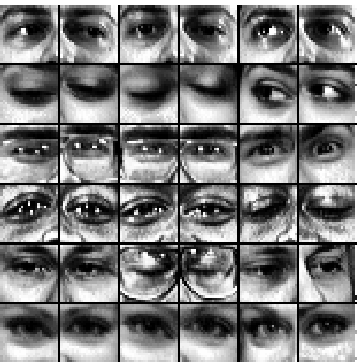
image. The extracted eye-images show considerable variation with respect
to open/closed eyes, expression, glasses (reflection in glasses) and gaze,
making this a challenging dataset. Some example eye-images are shown in
figure 1.
window at this region (for both
eyes). If this subwindow includes an area outside the original face image,
we pad the image with the mean of the gray-level values in the full face
image. The extracted eye-images show considerable variation with respect
to open/closed eyes, expression, glasses (reflection in glasses) and gaze,
making this a challenging dataset. Some example eye-images are shown in
figure 1.
Before feature extraction, all images were histogram equalized. As an additional preprocessor for the eigenfeature approach, the mean image was computed from the training set and subtracted from all the training and testing images.
 |